

The GSoC Coding Phase was divided into 2 phases. In the previous blog, we discussed about Coding Phase1. In this blog, we will discuss about different work done in Phase 2.
If you want to know more about the project, you can visit here.
Week 7 (July 3 – July 9)
Ambitions
- Work on the developing the codebook for the tags
- Work on developing a script for filtering tags from the metadata output file
Details
- I have developed a codebook which will contains all the tags listed in one place. The idea is to upload this to RedHen’s website after review.
- I also built a filtering script which will read the generated metatdata file (sfx), filter a tag within a certain timeframe and generate the output in a csv file.
Next Steps
- I am waiting for review of work from mentors
- Decide the next steps of transfer learning
Week 8 (July 10 – July 16)
Ambitions
- Finalise the ssfx script
- Review with mentors and decide the next steps
Details
I had a review with mentor with week. They have set the priorities for the next phase of work.
- Generate a TOP section for files without .seg.
- Finalise the codebook for reference
- Generate an advanced filtering mechanism to filter results for certain sound tags.
- Package code in Singularity container
- Check if it is possible to use the RedHen pipeline for audio processing
- Check for transfer learning and improving the result.
Strategies
I have finished the first 2 sections above. Now I am studying tools to generate the filtering. Austin has suggested to use JQ, which I am studying now. By the next week I plan to have my filtering output implemented and reviewed by mentors.
Week 9 (July 17 – July 23)
Ambitions
- Finalise the query using JQ
- Fixing review comments of mentors (like generating TOP for files not having .seg, etc)
Details
- Worked on the codebook. Wrote a script which will take the file with the YaMNet class mapping and generate a codebook file. In the process, it also does some formatting ( like removing the ‘,’ between tags and replacing them with ‘|’, string formatting, etc)
- Modify the ssfx script to generate TOP part when .seg files are not present.
- Generate a script to filter tags based on JQ query.
python ssfx.py "../samples/" 2022-01-01 2022-11-01 "(.Music // .Song), (.Television // .Radio)" 1
This will take the sfx file(s) from the “samples” folder (which are generated from the tagging script) and filters between the dates “2022-01-01” and “2022-11-01” and then filters the scores based on the query for each frame of data. The output will contain the timestamp where the tag is found and the scores for all the tags at that timestamp. The tags which are present in the SFX file and should be used for filtering are given in the code book
JQ has been used to generate the query for the tags. Some examples to make the queries are given below. These are standard JQ query formats.
"(.Music // .Song)"Filter the frames which contain tag with (Music or Radio)".Song, .Radio"Filter the frames which contain tags with Song and Radio"(.Music // .Song), (.Television // .Radio)"Filter the frames which contain tag with (Music or Radio) and (Television or Radio)
I am planning to have a review of the work with the mentors and go to the next step.
Week 10 (July 24 – July 31)
Ambitions
- Make some small changes in the ReadMe and scripts as suggested in review
- Package the code in singularity container and run in HPC
Details
To prepare the singularity container I followed those steps
- Create /scratch/users/$USER folder and clone the repo from here.
- Load the singularity
module load singularity/3.8.1 - Create Singularity sif file from docker container. To do this, go to /scratch/users/$USER folder and then run
singularity pull image.sif docker://ghcr.io/technosaby/gsoc2022-redhen-audio-tagging-stages:1 - Now execute the following command using the singularity exec command
singularity exec --bind /scratch/users/sxg1263/ image.sif python3 /scratch/users/sxg1263/gsoc2022/tagging_audio_effects/tools/audio_file_convertor.py -i /mnt/rds/redhen/gallina/tv/2022/2022-01/2022-01-01/ - /scratch/users/sxg1263/Output/AudioFiles/ -l 1"
As a start I wanted to convert all the video files for 2022-01-01 to audio files. Ideally the script should generate all audio files for the video files present in the date folder(2022-01-01) and put it inside the AudioFiles folder in Output of the scratch. But the output looks like this below and no files got generated. I only get this warning and no error.
“WARNING: While bind mounting ‘/scratch/users/sxg1263:/scratch/users/sxg1263/’: destination is already in the mount point list Starting generation of audio files from /mnt/rds/redhen/gallina/tv/2022/2022-01/2022-01-01/ to wav with format.”
- When the same command is run in my local LINUX PC using singularity sif file (created in the same way as above), it works fine and the audio files get generated correctly.
Setbacks
This week’s progress was very slow. Though I managed to prepare the container, I still struggled to run it correctly in the HPC. I am facing a wierd problem. When I run the command to access the video files from /mnt/rds/redhen/tv/ it does not work, but if I copy the video files to my scratch folder and run the singularity exec command, it runs fine.
As suggested by my mentor Ahmad, I tried running this on GPU using srun, but I faced the same problem.
Next Steps
- Fix the singularity problem. For now I am planning to copy the video files (for one month) in the scratch folder and run the scripts to finish the workflow
- FInd if there are other pre-trained models like YaMNet and how they perform
- Prepare about transfer learning -> (Discuss with Austin about strategies?)
Week 11 (Aug 1 – Aug 6)
Ambitions
- Finalise the singularity
- Discuss with mentors to finalise the next path
Details
- I have prepared the singularity container and had a review with Ahmed (my second mentor). He suggested some minor changes. But my singularity container is ready.
- The work to be done in the HPC is done in the form of a script
- I had a discussion with Austin about the next steps of the project for the next 1 month and after.
- In the next 1 month of the GSOC, we should try to port the SFX file to ELAN by converting into an EAF file. If we are able to do this, it will be a great help for the research community. Also we can write a paper about the same in the Linguistic Vanguard.
- If the ELAN does not work, the idea is to try out other Audio tagging libraries and see their performance along with YamNet.
- Also we have to check all the new papers written in the Audio Tagging and see if we can write a new paper after doing some modifications with the existing models. This can also result in a paper.
Next Week Targets
- Convert SFX to EAF file for ELAN portbility.
Week 12 (Aug 7 – Aug 13)
Ambitions
- Update the tag annotation in the ELAN TOOL.
- Review with mentors and decide the next course of actions
Ideas
I found an option in the ELAN tool which can import a CSV file. So I decided to use this approach to export the tags in a CSV file and import the annotations in ELAN tool.
Details
ELAN is a tool used by the research community to make and view annotations. So if we can add the audio tag annotations in the ELAN tool, then it will benefir the research community more as all the annotations will be on one place.
- I generated the tags in a CSV file (similar to SFX file).
- Then I imported the EAF file, MP4 file and the generated CSV file in the ELAN tool, the tag annotations can be seen as below.
- After discussion with Mark and Austin, I did a little modification, such that the Audio tags are set as tiers and the tagged frames are plotted as annotations in the ELAN tool.
- We can also format the ELAN output such that continuous tags can be plotted together. This will be taken in the next week.
Setbacks
None
Week 13 (Aug 14 – Aug 20)
Ambitions
- Finalize the project deliverables
- Review with mentors
- Finalize the singularity pipleine
Details
I have added a feature to filter the tagging before updating the CSVs files with scores specified by the user. If the user only wants to see the tags above .30 score, he/she can specify the score while calling the tagging script with the -c argument.
python tag_audio_effects.py -i <audio input path> -o <output data path (default: .)> -f <output file type (CSV) -c <csv_filter_score> -l <logs enabled (default 0) >
If this value is passed while generating the SFX file, then this parameter has no action.
Once that is done the generated CSV file will only contain scores above 0.30.
Final Week Ambitions
- Finalize the Singularity Container.
- Final review with mentors for GSoc.
- Run the tagger on files specified by the mentors.
- Start working for a paper to be submitted on our work in GSoc.
Week 14 (Aug 21 – Aug 27)
Ambitions
- Do more testing with more videos
- Fix existing bugs
- Check and finalize script on Singularity
Details
As we are entering into the last phase of the project, all the deliverables are ready. I have the scripts ready which can be run on a local as well as in HPC.
The following steps summarizes the execution of the Audio Tagger in HPC.
- Create a folder name with videos required for tagging or use an existing folder from RedHen’s mount point. Store it in a variable VIDEO_FILES.
VIDEO_FILES=/mnt/rds/redhen/gallina/tv/2022/2022-01/2022-01-01/If you are planning to create in the tags in SFX file, please ensure that you have the .seg files for your videos. - Please clone the repo in RedHen’s HPC as a scratch user in the home of the scratch user (e.g: /scratch/users/sxg1263/). After cloning you will have a gsoc2022 folder.
- Set all the variables as below
SCRATCH_USER=/scratch/users/$USER TOOLS_FOLDER=$SCRATCH_USER/gsoc2022/tagging_audio_effects/tools ROOT_FOLDER=$SCRATCH_USER/gsoc2022/tagging_audio_effects HOME_FOLDER=$SCRATCH_USER/gsoc2022 - Load the singularity container.
module load singularity/3.8.1 - In the scratch workspace, (e.g: /scratch/users/sxg1263/) create the singularity image from Github workspace.
singularity pull image.sif docker://ghcr.io/technosaby/gsoc2022-redhen-audio-tagging-stages:1 - Create temporary folders for Outputs. The AudioFiles folder will contain the converted audio files while the TaggedAudioFiles contain the tagged files.
mkdir Output/ cd Output || exit mkdir AudioFiles mkdir TaggedAudioFiles - Execute the following command to convert the video (from $VIDEO_FILES) to audio file im the wav format (in Output/AudioFiles).
singularity exec --bind $SCRATCH_USER $SCRATCH_USER/image.sif python3 $TOOLS_FOLDER/audio_file_convertor.py -i $VIDEO_FILES -a "wav" -o $SCRATCH_USER/Output/AudioFiles/ - Execute the following command to use the Audio Files generated from the last step to generate the Audio Tags in CSV (with confidence >= 0.2) and SFX format. The tags will be generated in TaggedAudioFiles folder.
singularity exec --bind $SCRATCH_USER $SCRATCH_USER/image.sif python3 $ROOT_FOLDER/tag_audio_effects.py -i $SCRATCH_USER/Output/AudioFiles/ -o $SCRATCH_USER/Output/TaggedAudioFiles/ -s 0.2 - After the script is run, an TaggedAudioFiles folders will be generated with the tagged audio files.
- You can now choose to copy the tagged files to your HPC home/PC for analysis using ELAN or JQ.
Some of the result samples for the videos in the RedHen video database are present here
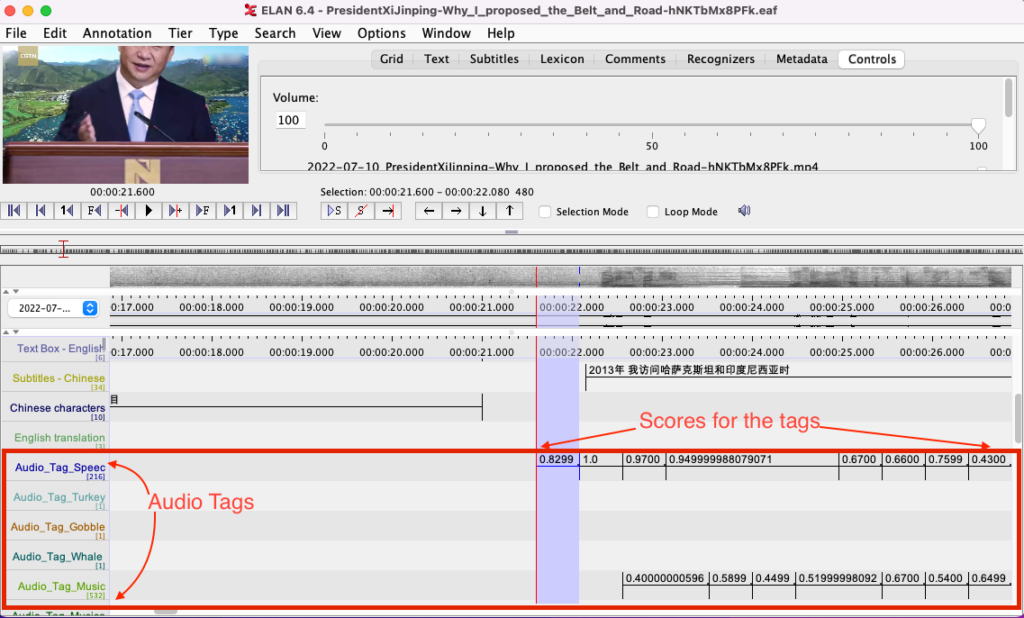
When a CSV file (e.g 2022-07-10_PresidentXiJinping-Why_I_proposed_the_Belt_and_Road-hNKTbMx8PFk.mkv) is imported in ELAN tool, some of the sample results are given below.
- Start of speech in video at 00:00:22 which is detected by YamNet at a confidence of 0.82
- Detection of silence when there is no audio in the video from 00:00:03 – 00:00:06