
The International Distributed Little Red Hen Lab, usually called “Red Hen Lab” is dedicated to research into multimodal communication. Red Hen develops computational, statistical, and technical tools.
Here I worked with Red Hen Lab to create a new, publicly-available, open-source pipeline, the Red Hen Audio Tagger (RHAT), which tags audio elements frame by frame via a deep learning model. These metadata tags can be captured in a variety of data formats and can be imported into tools like ELAN used for linguistic research. Once they are imported a linguistic researcher using ELAN can use RHAT to obtain automatic audio tagging and display it in ELAN annotation tiers, in parallel with other ELAN tiers.
Existing Red Hen pipelines tag for natural language processing of text, speech-to-text recognition, body pose and body keypoint analysis, optical character recognition, named entity recognition, computer vision, semantic frame recognition, and so on. RHAT works in conjunction with these other pipelines.
This project was done as a part of Google Summer of Code(GSoc) 2022 along with RedHen Labs. I have participated in GSoC’22 as a contributor and as a mentor in 2023.
Description
A single stream of data can contain multiple sound effects, so the goal is to label them from a group of known sound effects like a Multi-label classification problem. YaMNet is used as a pre-trained model in this project.
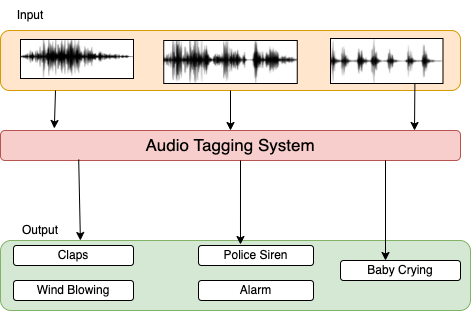
The project contains several blocks (in the form of scripts) which integrate together to annotate the tagging on RedHen videos. Each of the block is described below in details.
Generation of Audio File
Considering that the inout can be a video file, in the first step, the video files are converted into the audio files. This is done using the audio convertor script. The script uses the ffmpeg tool, which handles most of the common known video formats. In the context of our developed pipeline using YamNet, we only convert all the videos to the “wav” format with a sampling rate of 16000 due to restrictions in YamNet.
Tagging of Audio Files
Audio files contain samples captured over time which can be mapped into waveforms. The waveforms can be converted into a log-mel spectrogram which contains a visual representation of all the frequencies over time.
The below figure shows an example of a waveform (top) and a log-mel spectrogram(bottom) for a cat sound taken from the AudioSet data set. The Y axis of the spectrogram is the frequency is Hertz and the X axis is time(ms), the color represents the amplitude (in dB). The brighter color represents higher amplitude. Several studies have found that computer vision techniques, like Convolution Neural Network (CNN), can be applied on the images of the spectrograms to train a model to identify sounds with similar kinds of characteristics.

The process of generation of a log-mel spectrogram goes through a sequence of steps as given below. The log-mel spectrograms can be used as features which can then be framed into overlapping examples of fixed time thus generating patches. These patches can be used to train a deep learning (CNN based) model that can extract the dominant audio per time frame by finding patterns in them. There is also a concept of window framing, where some minimum length of input waveform is required to get the first frame of output scores.

All these work is done by YamNet and we use the pre-trained model to run on the converted audio files to generate the audio tags. These tags are dumped in 2 different kinds of files. All the work is done by the audio tagging script.
- SFX Files: These files are based on RedHen’s standards where tags are mapped with every frame of audio data. JQ queries can be used to filter the SFX tags.
- CSV Files: These files contain tags and their begin and end times for the frames. These CSV files are consumed by ELAN tool for annotations based on the tiers as sound effects.
The details and the use of each of the formats are given below.
Annotating the CSV results in ELAN
ELAN tool is a professional annotation tool to manually and semi-automatically annotate and transcribe audio or video recordings which is used by linguistic and gesture researchers all over the world. So we tried to import the CSV file generated by the audio tagger into the ELAN using the options as shown below. This is done by using the File->Import option after the video and the corresponding EAF file(ELAN annotation file) is loaded for that video.

The first column which consists of the the tags are mapped against the Tiers, the start and the end times of the tagged audio frames are tagged as Begin & End Time. The score for the tags is made as an Annotation.

After the import is done, the audio tags are shown along with the other annotations. The audio tags are plotted as tiers and the score of the tags are plotted on the video time frames along with the scores.

It is interesting to see that how nicely the tags are represented in the video timeline. The Speech of the video actually starts from 00:22 and it is detected with a confidence of 82%.
Parsing the SFX file
Another output file format is the SFX file, which is complaint to RedHen output formats. A sample SFX file will contain a TOP block with the file name along with other blocks like COL, UID, SRC, TTL, PID etc. These data are captured from .seg files sometimes present with the video in the RedHen database. Along with the blocks, it will contain the audio tags in a frame by frame basis along wth the scores. A sample SFX file might look like this below.

Sometimes the data in the SFX file can be overwhelming for a researcher to use or understand. So a special sfx file parser is written to parse and filter the metadata of tags. This filtering is done through JQ queries which can be passed along with the script as shown in the script documentation. Normally RedHen data are videos organized in the form of year, month and days. So if there is a set of generated SFX files in a folder and a researcher wants to filter between certain dates of files with a tag filter like Music or Speech, it can be passed with a JQ query and the output will be a filtered CSV file.